An introduction with information that is helpful to understand the analysis will follow later...
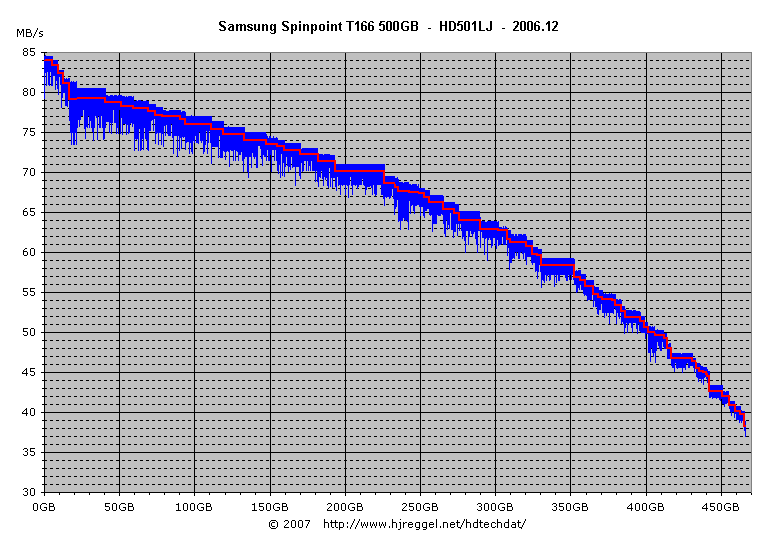
The transfer diagram with the sustained read rate
shows a clear upper shape with a jaggy area below:
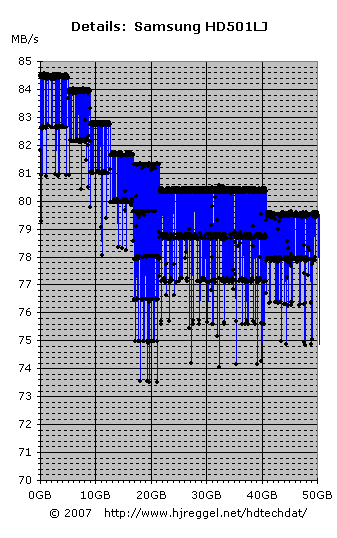 A closer look at the data reveals that the individual values
show discrete levels below the maximum of the different zones.
This is the typical look when idle revolutions happen
during the data transfer.
A closer look at the data reveals that the individual values
show discrete levels below the maximum of the different zones.
This is the typical look when idle revolutions happen
during the data transfer.
As base for the calculation, we take the fifth zone in
the diagram shown on the left. The sample size for the
measurement was 32MB, the regular transfer rate of this zone
is about 81.3MB/s. At 7200RPM, the disk makes about 48 revolutions
while reading the data.
If you calculate the effective data rate when there are
idle revolutions during the transfer, the resulting data rates are:
1 idle rev.: 79.6MB/s
2 idle rev.: 78.0MB/s
3 idle rev.: 76.4MB/s
4 idle rev.: 74.9MB/s
5 idle rev.: 73.6MB/s
These are exactly the transfer rates of the measurements
that are within the fifth zone, but below 81.3MB/s.
What does this mean? In most cases, everything is fine. But there are situations, where there are a few idle revolutions in addition to the 48 revolutions (outer tracks) to 100 revolutions (inner tracks) required to read the 32MB data. The worst cases are equal to one idle revolution within ten regular revolutions. I can't tell the overall ratio of idle revolutions compared to the minimum required, but I can tell that there are many other harddisks that don't show such strange behaviour. The sustained data rate is about 1MB/s less than it could be, but the difference gets bigger when reading a smaller amount of data is affected by these idle revolutions.
Why does this happen? The disk might have too short head and/or cylinder skew, which means that the disk does not manage to get a "target lock" on the next track before the first sector of that track comes by. Other reasons might be that the disk loses track of the data and has to wait for the next turn, or that there are errors in the readout forcing a retry for the current sector.
But in all these situations, read-ahead and caching strategies
should be able to compensate for this: For each
lower peak there should be an upper peak when the
data that was read ahead is delivered from the cache.
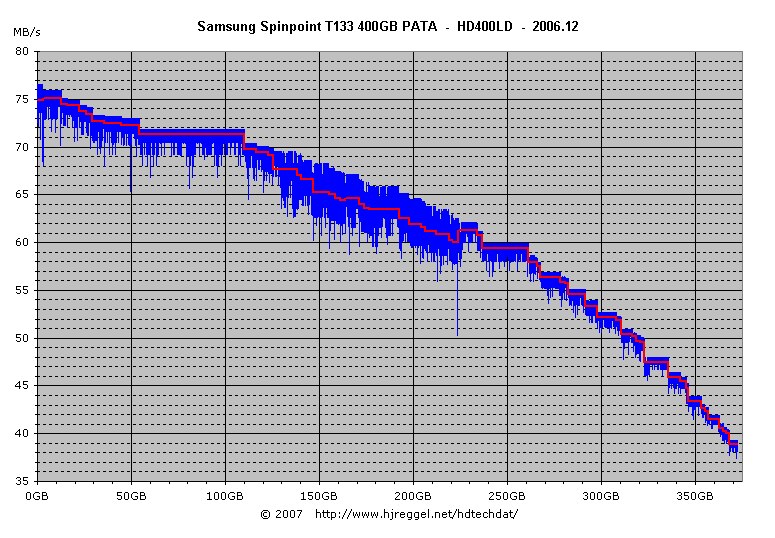
The transfer diagram of the HD400LD looks even worse than
that of the HD501LJ:
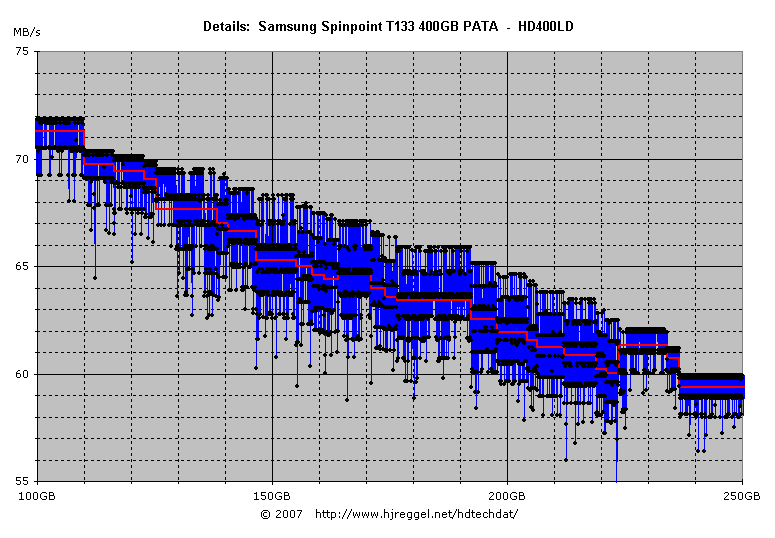
The part in the middle from zone 14 up to the beginning of
zone 32 (from 125GB to 225GB) looks very rough, and the
disk hardly reaches its design rate:
Tests on a completely different system resulted in a different look of the graph. The first 55GB were clipped to about 72MB/s, the area between 125GB and 225GB was not worse than the other areas, but there was a significant drop between 275GB and 295GB. This means that there are problems in continuity and timing problems between disk and host controller. More details will follow after the next test runs...